|
Theory
|
|||
| Select topic | Area Correlation SIMD Instruction | ||
|
|
||
|
|
|
 |
|
 |
|
 |
Original image with selected area of interests (red square). |
 |
Coefficient of Un Normalized Area correlation (white is highest) |
 |
Result. This result illustrate, that is necessary to use normalization during the calculation. |
 |
Coefficient of Normalized Area correlation (white is highest) |
 |
Result. The result is right. |
|
SIMD - single instruction, multiple data; SIMD technology in CPU: The MMX technology uses the single instruction, multiple data (SIMD) technique for performing arithmetic and logical operations on the bytes, words, or doublewords packed into MMX registers. For example, the PADDSW instruction adds 4 signed word integers from one source operand to 4 signed word integers in a second source operand and stores 4 word integer results in the destination operand. (Note that the same MMX register is generally used for the second source and the destination operand.) This SIMD technique speeds up software performance by allowing the same operation to be carried out on multiple data elements in parallel. The MMX technology supports parallel operations on byte, word, and doubleword data elements when contained in MMX registers. The SIMD execution model supported in the MMX technology directly addresses the needs of modern media, communications, and graphics applications, which often use sophisticated algo-rithms that perform the same operations on a large number of small data types (bytes, words, and doublewords). For example, most audio data is represented in 16-bit (word) quantities. The MMX instructions can operate on 4 words simultaneously with one instruction. Video and graphics information is commonly represented as palletized 8-bit (byte) quantities. Here, one MMX instruction can operate on 8 bytes simultaneously. |
|
 |
Single Instruction, Multiple Data (SIMD) Execution Model |
 |
Typical architecture of processor with SIMD. Scheme AMD K6-III, contains ten execution pipelines—store, load, integer X ALU, integer Y ALU, MMX ALU (X), MMX ALU (Y), MMX/3DNow! multiplier, 3DNow! ALU, Floating-Point, and Branch.
|
 |
X and Y modules can work simultaneously. It's typicaly for Intel Pentium MMX and above, AMD K6-2 and above, VIA C3.. |
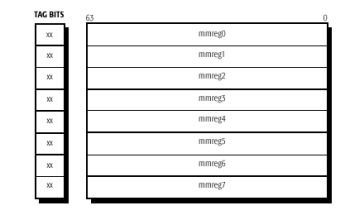 |
Mapping the MMX registers on the floating-point stack enables backwards compatibility for the register saving that must occur as a result of task switching. |
 |
MMX data Packed byte |
 |
SSE/SSE2 instruction. In Intel Pentium III and AMD Athlon XP exist SSE registers - 8 x 128bit. SSE support 32bit floating-point operation. SSE2 and Intel Pentium 4 processor add support for 8, 16, 32 64 bit integer data in XMM(SSE) registers. |
 |
SSE2 128-Bit Packed Double- Precision Floating-Point; |
 |
AMD Hammer (x86-64) architecture
will support: *64-bit virtual addresses (implementations can have less). *Register extensions through a new prefix (REX): - Adds eight GPRs (R8–R15). - Widens GPRs to 64 bits. - Adds eight 128-bit streaming SIMD extension (SSE) registers (XMM8–XMM15). *64-bit instruction pointer (RIP). |
 |
The AltiVec technology extends the instruction set architecture (ISA) of the PowerPC architecture. AltiVec technology is a short vector parallel architecture. The AltiVec ISA is based on separate vector/SIMD-style (single instruction stream, multiple data streams) execution units that have high data parallelism. |
|
Literature: - The IA-32 Intel Architecture Software Developer’s Manual
consists of three volumes: Basic Architecture, Order Number 245470
- 24547004.pdf; |
|